
Gemini 2.5 Pro:グーグルのAI覇権奪還への挑戦 – その実力は?
Gemini 2.5 Proは、グーグルがこれまで開発した中で最も進んだAIモデルと言われています。高度な推論能力、数学や科学の分野での優れたパフォーマンス、そして最大100万トークン(倍増計画あり)という巨大なコンテキストウィンドウを誇ります。実験的にリリースされ、現在は無料で利用できるGemini 2.5 Proは、AI業界に向けてグーグルが明確なメッセージを送るものです。「競争はまだ終わっていない。グーグルは再びゲームに戻ってきた」と。
しかし、その製品は約束に見合うものでしょうか?
ユーザーからのフィードバックやベンチマークが出回り始めると、話題は発表時の盛り上がりから、より詳細な検証へと移っています。特に、AI開発競争の行方を見守る企業のリーダー、開発者、投資家の間で、その傾向が顕著です。Gemini 2.5 Proが注目に値する理由、優れている点、注意すべき点について解説します。
1. 内部構造:Gemini 2.5 Proの新機能
Gemini 2.5 Proは、単なるバージョンアップではありません。2025年のグーグルのAI戦略の基盤となる、大幅なアーキテクチャのアップグレードです。
- 統合された推論能力:強化された推論エンジンを搭載し、Gemini 2.5 Proは洗練された強化学習と連鎖的思考アプローチを使用しています。ベンチマークでは、ツールなしでの推論タスクで業界をリードしています。
- マルチモーダル対応:テキスト、画像、音声、ビデオ入力へのネイティブサポートはそのままです。これにより、Geminiはさまざまな形式を統合する必要がある複雑なデータセットの処理において優位性があります。
- 大規模なコンテキスト処理:100万トークンというコンテキストウィンドウ(競合他社の2倍)により、Geminiは大量のドキュメント、巨大なコードベース、長時間の会話に最適化されています。200万トークンのウィンドウもすでにテスト中です。
- コーディング能力:このモデルは、SWE-bench verifiedタスクやAider Polyglotなどの新しいベンチマークで高いスコアを獲得しています。まだ自律的なコーディングワークフローでは支配的ではありませんが、その差は縮まっています。
- デプロイオプション:現在、Google AI StudioとGemini Advancedを通じて無料で利用でき、Vertex AIとの統合も計画されています。本格的な商用価格は間もなく発表される予定です。
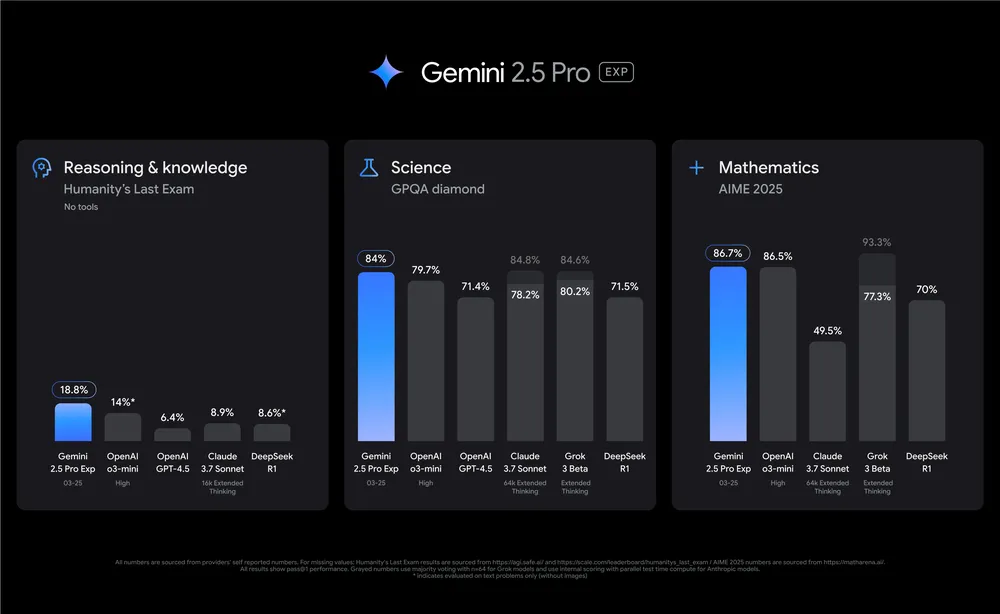
2. ベンチマークデータ:Gemini 2.5 Proが優れている点
推論と知識
ゼロショット、ツールなしの条件下では、Gemini 2.5は複雑な推論タスクで18.8%のスコアを獲得しました。これはGPT-4.5(6.4%)の3倍、DeepSeek R1(8.6%)を大きく上回っています。そのため、企業分析、法務解析、戦略モデリングなどの分野で強力な選択肢となります。
数学と科学(AIME & GPQA)
Gemini 2.5は、AIME 2024ベンチマークで92.0%のスコアを記録し、2025年では86.7%を記録しました。これはClaude、Grok、さらにはOpenAIの最新のo3-miniを大きく上回っています。金融、エンジニアリング、学術分野の企業にとって、この数学的能力は大きな生産性向上につながる可能性があります。
マルチモーダル理解
視覚的推論(81.7%)と画像理解(69.4%)は、堅牢なマルチモーダルパフォーマンスを示唆しています。特に、Gemini 2.5は画像理解でスコアが報告された唯一のモデルであり、異なる形式間の理解におけるリーダーとなっています。
コンテキスト保持
Geminiは、長期コンテキストベンチマークで91.5%と83.1%のスコアを獲得し、OpenAIのo3-mini(36.3%と48.8%)を上回っています。この能力は、複数ドキュメントの整合性が不可欠な法務、技術、研究ワークフローに不可欠です。
多言語対応
Global MMLU Liteベンチマークで高いスコア(89.8%)を獲得したことは、Geminiが言語を越えて処理および推論できる能力を示しており、国境を越えた企業や多国籍展開において重要な資産となります。
3. Gemini 2.5 Proがまだ劣る点
Gemini 2.5 Proには、強みがある一方で、特にニッチなタスクでは競合他社に比べて不足している点があります。
コード生成
高いパフォーマンス(LiveCodeBench v5で70.4%)を発揮していますが、OpenAIのo3-mini(74.1%)には及びません。自律的なコードエージェントや内部ツールパイプラインを構築する企業にとって、これは大規模な効率を制限する可能性があります。
エージェント型コーディング
GeminiはSWE-bench verifiedベンチマークで63.8%のスコアを獲得し、Claudeの70.3%を下回っています。「AIがAIを構築する」ことへの企業からの需要が高まり続けているため、これは注目に値します。
事実の正確性
SimpleQAでは、Geminiは52.9%のスコアを獲得し、GPT-4.5の62.5%を下回っています。信頼性の高いアプリケーション(金融、医療、カスタマーサービス)では、この精度ギャップが信頼性に影響を与える可能性があります。
4. 実際の評価:ユーザーと開発者の意見
RedditやX(旧Twitter)などのフォーラムでは、反応はさまざまです。
- パワーに対する称賛:開発者はその高度な推論とネイティブなマルチモーダリティを強調し、他の人はグーグルの2025年の知識カットオフ(市場初)を称賛しています。
- アクセスと安定性に対する批判:ユーザーはプラットフォーム全体で一貫性のない可用性を報告しており、Gemini 2.5のパフォーマンスはGemini 2.0 Flashのような以前のバージョンと同程度だと考えている人もいます。繰り返されるコメントの1つは、「革命というよりは、堅実な改善のように感じます」ということです。
- 開発者の懸念:構造化された出力(JSONなど)、デプロイエージェント、ロールアウトのタイムラインに関する質問は、発表された機能と実際の有用性との間にミスマッチがあることを示唆しています。
5. 競争環境:業界の転換点
AI分野は、規模よりも専門化へと収束しています。Gemini 2.5 Proは強力ですが、費用対効果と垂直最適化が真の戦場となりつつある市場に参入します。
- OpenAIのo3シリーズは、エージェント型の動作とコーディングタスクで引き続きリードしています。
- Claude 3.7 Sonnetは、事実性と自律的な推論において依然として強力です。
- DeepSeek R1は、低いコンピューティングコストで印象的なパフォーマンスを発揮するダークホースとして台頭しており、既存企業に価格設定とアクセシビリティの見直しを迫っています。
投資家にとって、これはエコシステムの成熟を示すものです。モデルが一般的なベンチマークで能力飽和に近づくにつれて、差別化は統合、デプロイの安定性、推論1ドルあたりのROIから生まれるでしょう。
Gemini 2.5 Proは明確なシグナル – しかし最終的な答えではない
Gemini 2.5 Proは、グーグルがこれまでで最も優れたAIモデルです。推論、長期コンテキスト理解、マルチモーダルタスクでリーダーシップを確立しています。しかし、すべてのカテゴリで支配的というわけではありません。そして、ユーザーはすでに可用性、完全性、価値について厳しい質問をしています。
企業にとって、Gemini 2.5 Proは特に知識集約型の分野で、魅力的なツールキットを提供します。投資家にとって、これは業界全体のより大きなモデルの構築から、より優れたモデルの構築への転換を反映しています。
主なポイント:
- Gemini 2.5 Proは、特に推論とコンテキストが豊富なタスクにおいて、技術的な飛躍を遂げています。
- ベンチマークは、グーグルの競争力が回復したことを確認していますが、事実の正確性とエージェント型ワークフローにおける重要なギャップも強調しています。
- 実際の導入は、配信速度、価格設定の明確さ、開発者との信頼関係の構築にかかっています。