
アリババ、Google & OpenAI に照準:見て、聞いて、話せるオープンソースAI、Qwen2.5-Omni
AIの開発競争は、新たな主要プレイヤーの登場でさらに激化しています。GoogleのGeminiやOpenAIが、画像、動画、音声、テキストを理解するマルチモーダル機能で私たちを驚かせている一方で、アリババのQwenチームは、潜在的な爆弾となる「Qwen2.5-Omni」をひっそりと発表しました。これは単なる大規模言語モデルではありません。「全方向対応」のマルチモーダルAIとして、私たちが世界を知覚する方法により近い形で設計されています。テキスト、画像、音声、そして動画を処理し、テキストだけでなく、リアルタイムで合成音声で応答します。
おそらく最も革新的な点は、アリババが70億パラメータバージョンのQwen2.5-Omni-7Bを、Apache 2.0ライセンスの下でオープンソース化したことです。この動きは、高度なマルチモーダルAIツールを、世界中の開発者や企業が商用利用を含めて自由に使用できるようにする可能性を秘めています。これは大胆な戦略であり、主要な競合他社の囲い込み戦略に挑戦するものです。
その仕組みは? 「Thinker-Talker」アーキテクチャ
アリババは、既存のLLMに感覚機能を単に追加しただけではありません。彼らは、斬新な**「Thinker-Talker」アーキテクチャ**を導入しました。
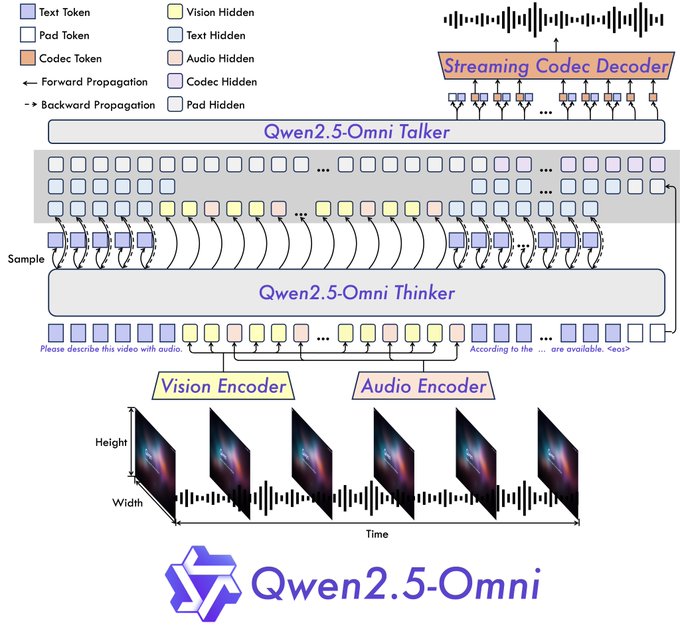
- Thinker(思考者): このコンポーネントは、脳のように機能します。テキスト、ビジュアル、サウンドといった多様な入力を受け取り、それらを処理して、コンテキストを理解し、高度な意味表現を生成するとともに、中心となるテキスト応答を生成します。オーディオとビジョンには専用のエンコーダを使用し、関連する特徴を抽出します。
- Talker(話者): 口や声帯のように機能するTalkerは、Thinkerからリアルタイムで意味情報とテキストを受け取ります。次に、これを離散的なオーディオトークンに合成し、記述されたテキストとともに、自然な音声ストリームを生成します。
このエンドツーエンドの設計は、リアルタイムでインタラクティブな体験を実現するために不可欠です。このアーキテクチャは、チャンク化された入力と即時の出力をサポートし、ターン制のチャットよりもビデオ通話に近い感覚の会話を目指しています。
さらに、Qwen2.5-Omniは、**TMRoPE(時間調整マルチモーダルRoPE)**と呼ばれる新しい位置埋め込み技術を組み込んでいます。これは、共有タイムラインに沿って、ビデオフレームを対応するオーディオセグメントと正確に同期させるという、扱いにくい問題に特に対処するものです。これを正しく行うことは、ビデオコンテンツ内のアクションとスピーチを正しく理解するために不可欠です。
性能に関する主張 vs. 実際のテスト:優れた感覚機能、疑わしい知性?
アリババは、Qwen2.5-Omniが、統合されたマルチモーダルタスク用に設計されたベンチマークであるOmniBenchで、最先端の結果を達成したと主張しています。また、GoogleのGemini 1.5 Proのようなクローズドソースの競合製品を含む、同様のサイズのモデルよりも、特定のタスクで優れたパフォーマンスを発揮し、独自のラインナップからの専門的なシングルモーダルモデル(ビジョン用のQwen2.5-VL-7Bやオーディオ用のQwen2-Audioなど)よりも優れていると報告しています。
公式のデモと初期のユーザテストは、魅力的ではあるものの、評価が分かれる結果を示しています。
- 良い点 – マルチモーダルにおける優れた能力:
- 視覚: シミュレートされたセキュリティフィード画像内の「不審な行動」を正確に識別し、正しい分類と推論を提供しました。
- 動画: ダンス動画を与えられた場合、ダンサーの服装、動き、設定に関する詳細な説明を提供しました。
- 音声: アップロードされた音声レシピから、豚の角煮を作るための手順を正しく要約しました。
- インタラクション: 同時テキストと自然な音声出力(英語/中国語の混在をうまく処理)は高速かつスムーズで、真に会話的な感覚を生み出します。デモでは、AIが周囲の状況を説明したり、音声ガイド付きのレシピアシスタントとして機能したり、曲の下書きを批評したり、スケッチを分析したり、写真から数学の問題をステップごとに指導したりするビデオ通話を紹介しています。
- 悪い点 – 推論の不具合と実践的なハードル:
- 基本的な論理の失敗: 高度な感覚処理にもかかわらず、7Bデモモデルは単純な推論タスクでつまずきました。「6.9と6.11のどちらが大きいですか?」と尋ねられたところ、6.9の方が小さいと誤って答えました。「strawberry」には何個の「r」がありますか?と尋ねられたところ、2つと答えました(3つあります)。これは、少なくともこのアクセス可能なバージョンでは、知覚能力と認知推論の間に潜在的なギャップがあることを示唆しています。
- リソースの集中: モデルをローカルで実行しようとした一部のユーザーは、かなりのVRAM要件を報告しており、ある例では、21秒のビデオで100GBのVRAM設定でOut-of-Memoryエラーが発生したと述べています。他のユーザーは、大きな画像でのエラーや遅い生成時間(応答あたり数分)を指摘しており、効率的なデプロイには最適化または特定のハードウェア構成が必要になる可能性があることを示唆しています。
- 言語とカスタマイズ: 英語と中国語の音声出力は強力ですが、ユーザーはスペイン語やフランス語などの他の言語での制限を指摘しました。現在の音声出力はテキストを反映しています。特定のアプリケーションでは、より多くのカスタマイズオプションが有益でしょう。専門家ではないユーザー向けのアクセシビリティも、改善が必要であると指摘されました。
オープンソース化という賭け:マルチモーダルAIの民主化?
アリババが、商用利用が可能なApache 2.0ライセンスの下でQwen2.5-Omni-7Bをオープンソース化するという決定は、おそらくこのリリースの最も戦略的に重要な側面です。
- 障壁の引き下げ: これにより、スタートアップ、研究者、さらには大手企業まで、クローズドモデルに関連する法外なAPIコストやライセンス料なしに、高度なマルチモーダルAIを試して展開できます。これにより、次のような分野でのイノベーションが促進される可能性があります。
- アクセシビリティツール: 視覚障碍者のために世界を説明できるAI。
- 教育: 学生の作品を見て、質問を聞くことができるインタラクティブな家庭教師。
- クリエイティブアシスタンス: 複数の入力に基づいて、視覚芸術、音楽、または文章を批評するツール。
- スマートデバイス: ウェアラブル(ユーザーが言及したスマートグラスのコンセプトなど)またはホームアシスタントとのより自然なインタラクションを可能にします。
- 競争圧力: この動きは、OpenAIとGoogleのビジネスモデルに直接挑戦し、価格設定を再検討するか、独自の最先端モデルのよりアクセスしやすいバージョンを提供するよう強制する可能性があります。この動きを「真のOpenAI」と呼ぶユーザーのコメントは、強力なオープンツールを切望する開発者コミュニティの一部を反映しています。
- エコシステムの構築: アリババにとって、これはQwenモデルを中心に開発者エコシステムを構築し、より幅広い採用を促進し、モデルもホストされているクラウドプラットフォームの使用を促進するための戦略である可能性があります。
まとめ:力強い一歩、しかし旅は続く
Qwen2.5-Omniは、特に多様な入力をシームレスに統合し、斬新なアーキテクチャ内でリアルタイムのテキストおよび音声出力を実現している点で、マルチモーダルAIにおける間違いなく重要な進歩です。7Bモデルのオープンソース化は、AIの状況に大きな影響を与える可能性のある大きな動きであり、世界中の開発者や企業に力を与えます。
ただし、初期テストでは、重要な現実が浮き彫りになっています。高度な感覚知覚が、完璧な推論や簡単なデプロイに自動的に変換されるわけではありません。観察された論理エラーと報告されたリソース要件は、克服すべきハードルがまだあることを示しています。
企業や投資家にとって、Qwen2.5-Omniは機会と観察点の両方を表しています。機会は、この強力でアクセス可能なツールをイノベーションに活用することにあります。観察点は、モデルがどのように成熟し、コミュニティがその制限にどのように対処し、競合他社がこのオープンソースの課題にどのように対応するかを見守ることです。アリババは強力なカードを切りました。AIのハイステークスゲームにおける次の動きが、熱心に待たれています。
リソース:
- デモ: https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
- Qwenチャット体験: https://chat.qwen.ai/
- GitHub: https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Faceモデル: https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- 技術レポート: https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
- ブログ記事: https://qwenlm.github.io/blog/qwen2.5-omni/